本文主要介绍了大数据性能测试工具 HiBench 的基本概念,配置文件,介绍了 Spark 的 Teasort 和 WordCount 性能测试,并提供了测试脚本。
简介
HiBench是一个大数据基准套件,可帮助评估速度、吞吐量和系统资源利用率方面的不同大数据框架。 它包含一组Hadoop,Spark和streaming测试模式,包括Sort,WordCount,TeraSort,Repartition,Sleep,SQL,PageRank,Nutch indexing,Bayes,Kmeans,NWeight和增强的DFSIO等。它还包含一些用于Spark流的流工作负载 ,Flink,Storm和Gearpump。
源码地址
Intel-bigdata/HiBench: HiBench is a big data benchmark suite.
https://github.com/Intel-bigdata/HiBench
编译文件
这里提供编译好的文件,下载地址:
https://pan.baidu.com/s/11X_SxFyQLxrT45wm6XMoXg
提取码:zz75
目录结构
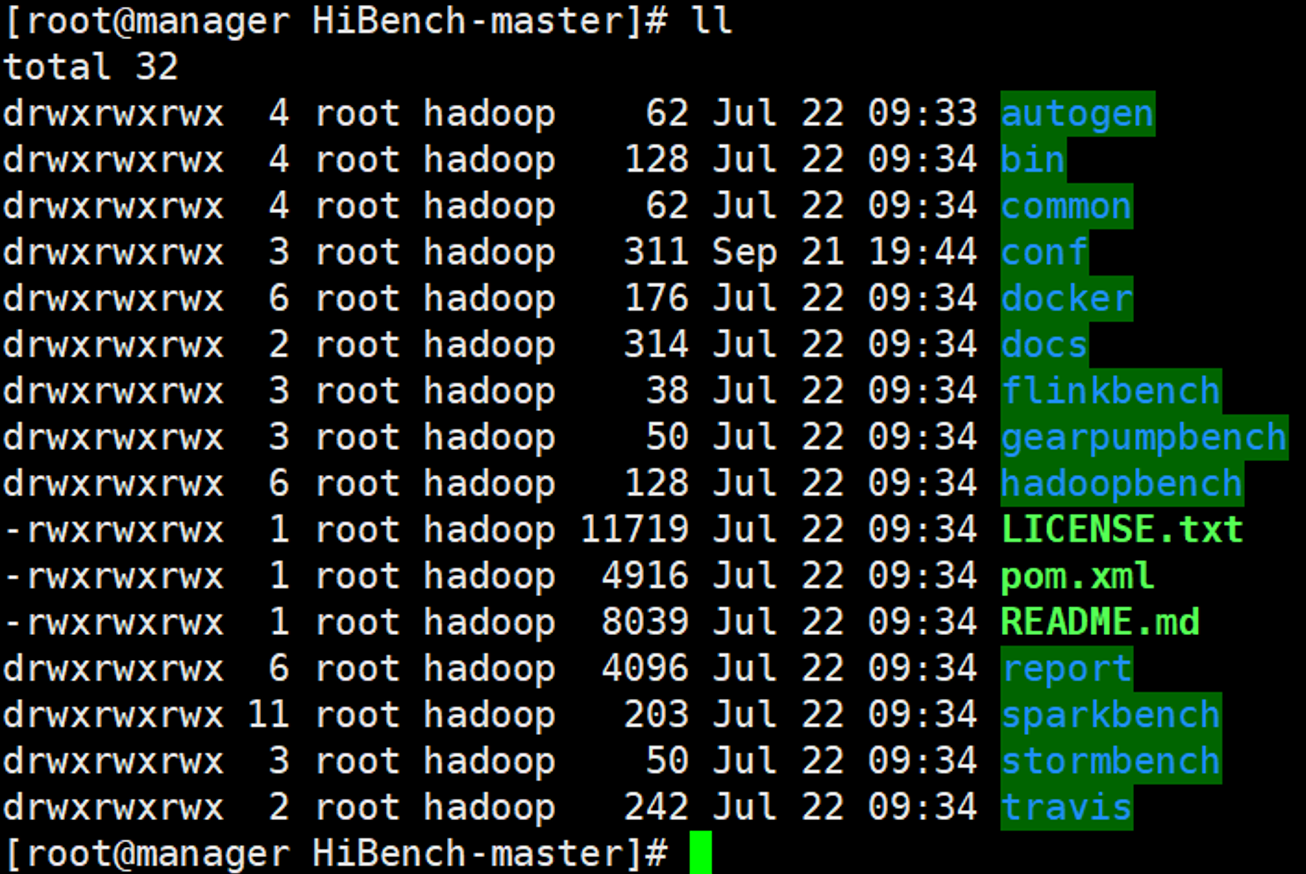
- autogen:主要用于生成测试数据的源码目录
- bin:测试脚本放置目录
- common:公共依赖源码目录
- conf:配置文件目录(Hibench/Hadoop/Spark等配置文件存放目录)
- docker:HiBench的docker镜像
- flinkbench:Flink框架源码目录
- gearpumpbench:gearpumpbench框架源码目录
- hadoopbench:hadoop框架源码目录
- sparkbench:spark框架的源码目录
- stormbench:storm框架的源码目录
配置文件
hibench.conf
主要配置HiBench的运行参数及HiBench各个模块的home环境配置。
其中需要注意的参数为:
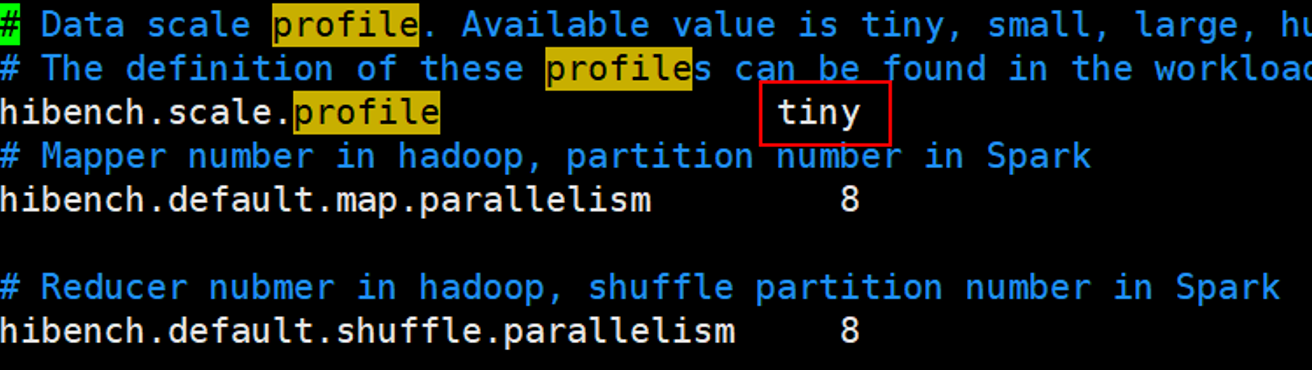
- hibench.scale.profile:主要配置HiBench测试的数据规模,有tiny, small, large, huge, gigantic 和bigdata六个级别;
- hibench.default.map.parallelism:测试MapReduce时是Mapper数量,测试Spark时是分区数;
- hibench.default.shuffle.parallelism:测试MapReduce时是Reduce数量测试Spark时是shuffle分区数。
数据规模
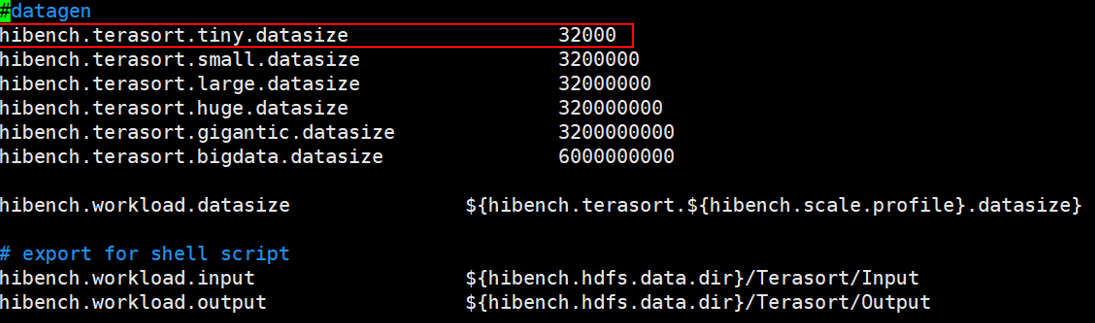
数据规模对应的数据量在HiBench-master/conf/workloads/micro目录中设置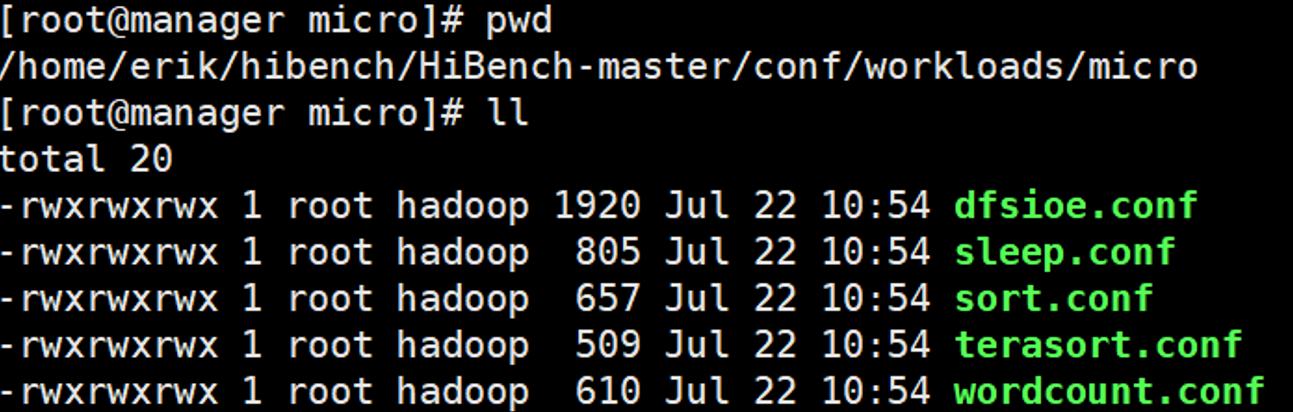
dfsioe.conf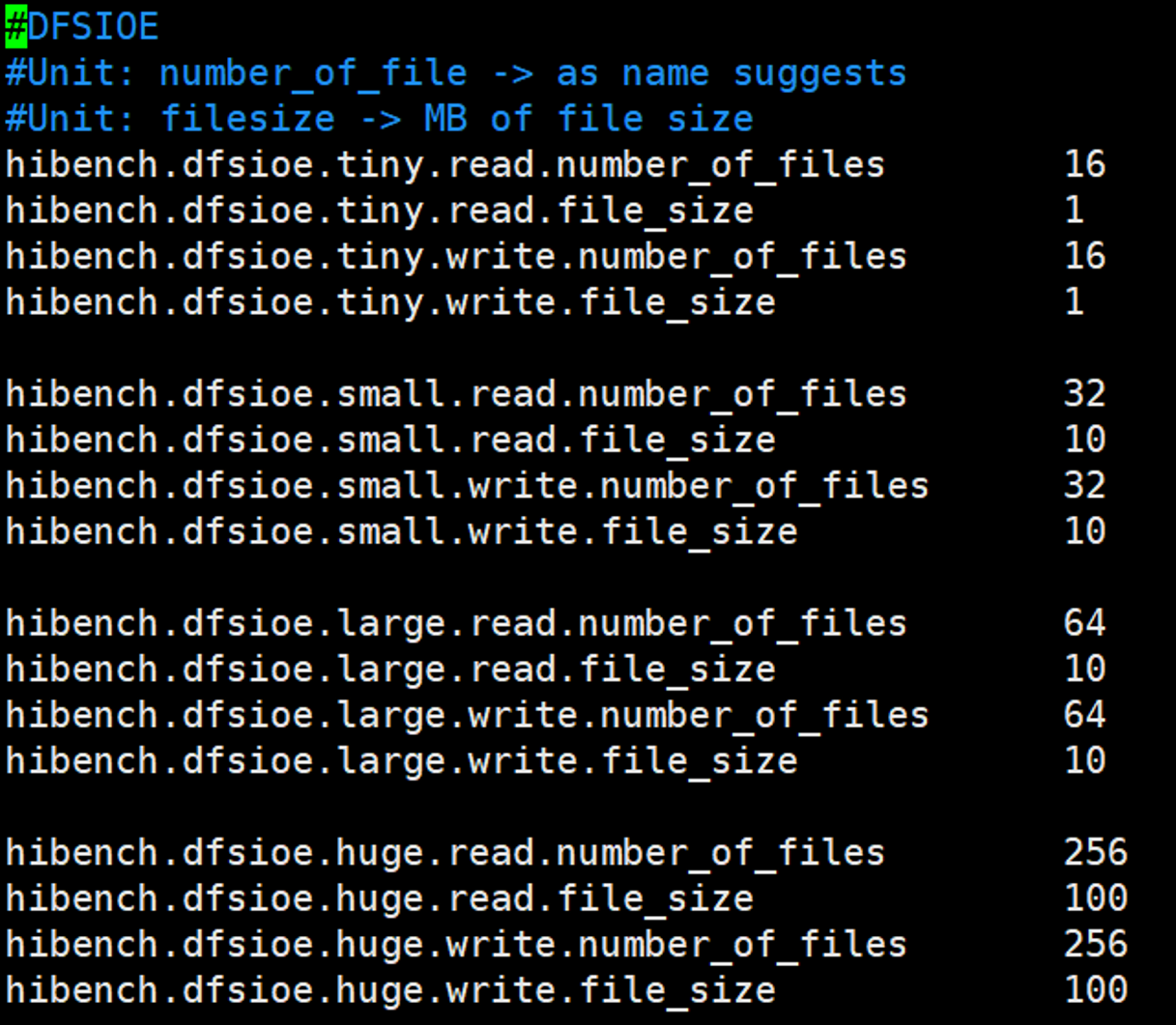
| 数据规模 | 读文件数 | 读文件单个大小(MB) | 写文件数 | 写文件单个大小(MB) |
|---|---|---|---|---|
| tiny | 16 | 1 | 16 | 1 |
| small | 32 | 10 | 32 | 10 |
| large | 64 | 10 | 64 | 10 |
| huge | 256 | 100 | 256 | 100 |
| gigantic | 512 | 400 | 512 | 400 |
| bigdata | 2048 | 1000 | 2048 | 1000 |
DFSIOE测试用例通过定义读或写的文件数和文件的大小来指定测试数据量的规模,如果需要自定义测试规模则修改文件数和文件的大小即可,文件大小以MB为单位。
terasort.conf
数据量配置以条数为单位,每条数据约100byte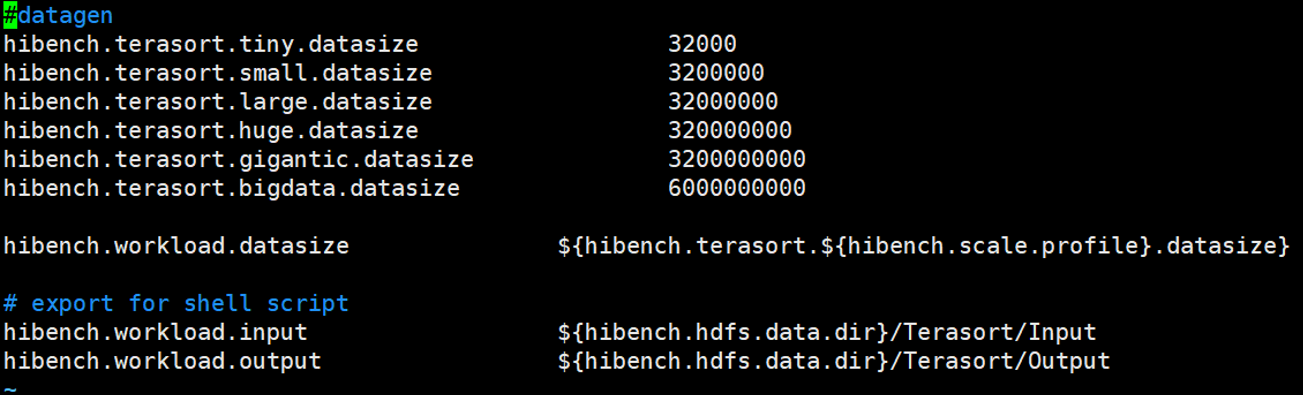
比如,定义100G数据,则应设置为10010241024*1024/100=1073741824
设置数据,既可修改原来的数据,也可以自定义数据规模
wordcount.conf
数据量配置以byte为单位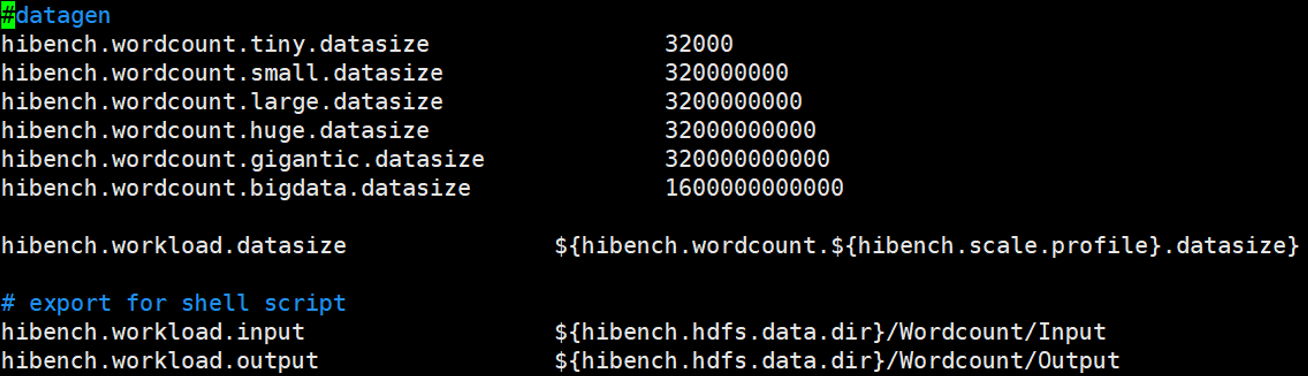
比如,要设置100G数据量,为10010241024*1024=107374182400
hadoop.conf.template
hadoop.conf.template为测试Hadoop时的配置模板,测试Hadoop时需要重命名为hadoop.conf
1 | cp hadoop.conf.template hadoop.conf |
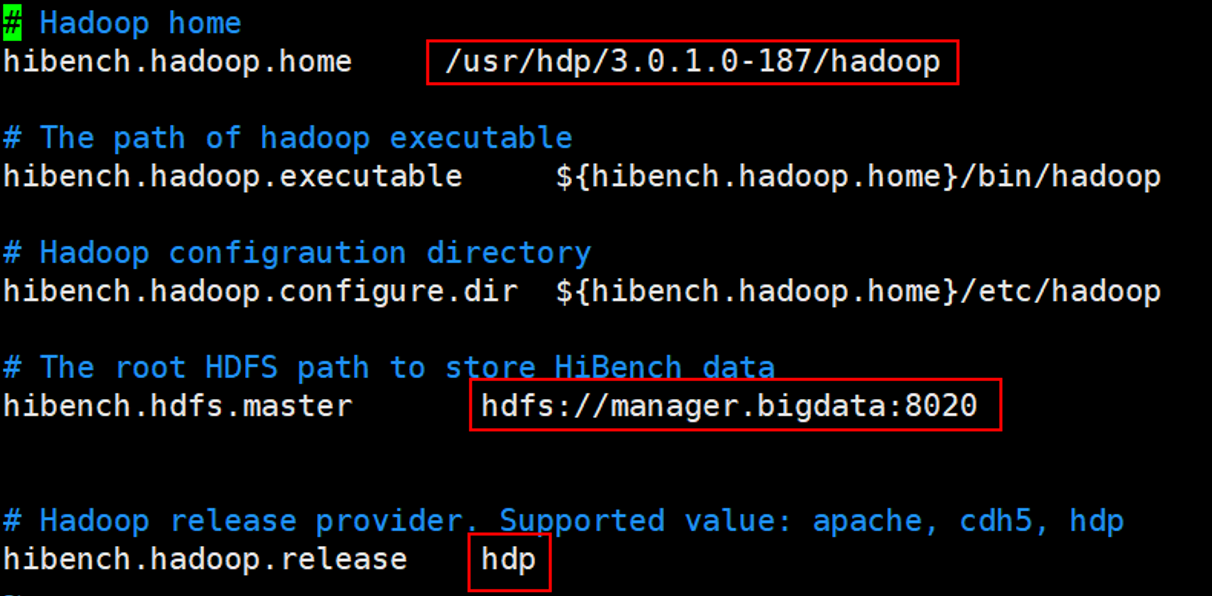
主要修改hibench.hadoop.home、hibench.hdfs.master和hibench.hadoop.release三个参数,过HDFS启用HA模式,则hibench.hdfs.master设置为HA对应的访问方式。
spark.conf.template
spark.conf.template为Spark测试时的配置文件,测试Spark时需要重命名为spark.conf
1 | cp spark.conf.template spark.conf |
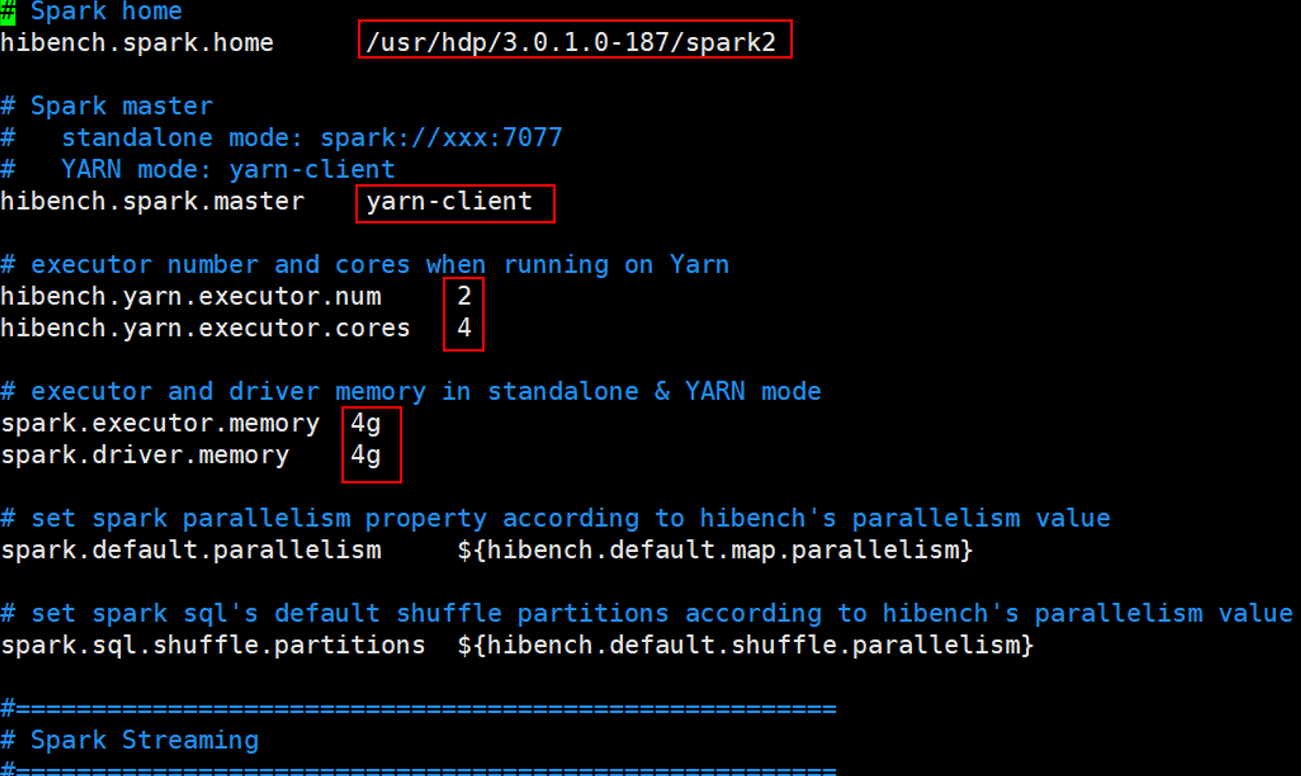
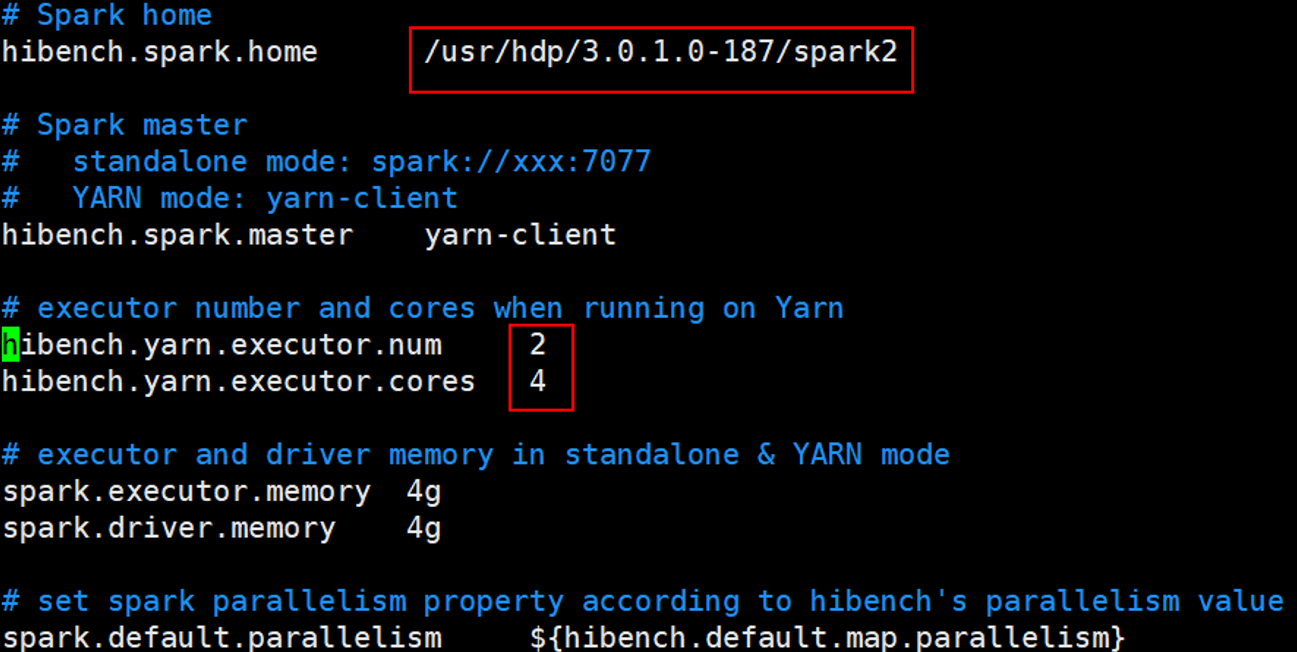
根据实际情况设置hibench.spark.home,hibench.spark.master为根据spark是standalone模式还是Yarn模式进行设置。当hibench.spark.master为yarn-client时,通过Yarn的ResourceManager的UI界面查看资源信息,然后设置hibench.yarn.executor.num、hibench.yarn.executor.cores、spark.executor.memory、spark.driver.memory进行性能调优。
Spark 性能测试
Teasort
这里以最小的数据量 tiny 为例介绍 Spark 的 Teasort 性能测试步骤。
1 | cd /home/erik/hibench/ |
修改配置文件
1 | cd HiBench-master/conf/ |
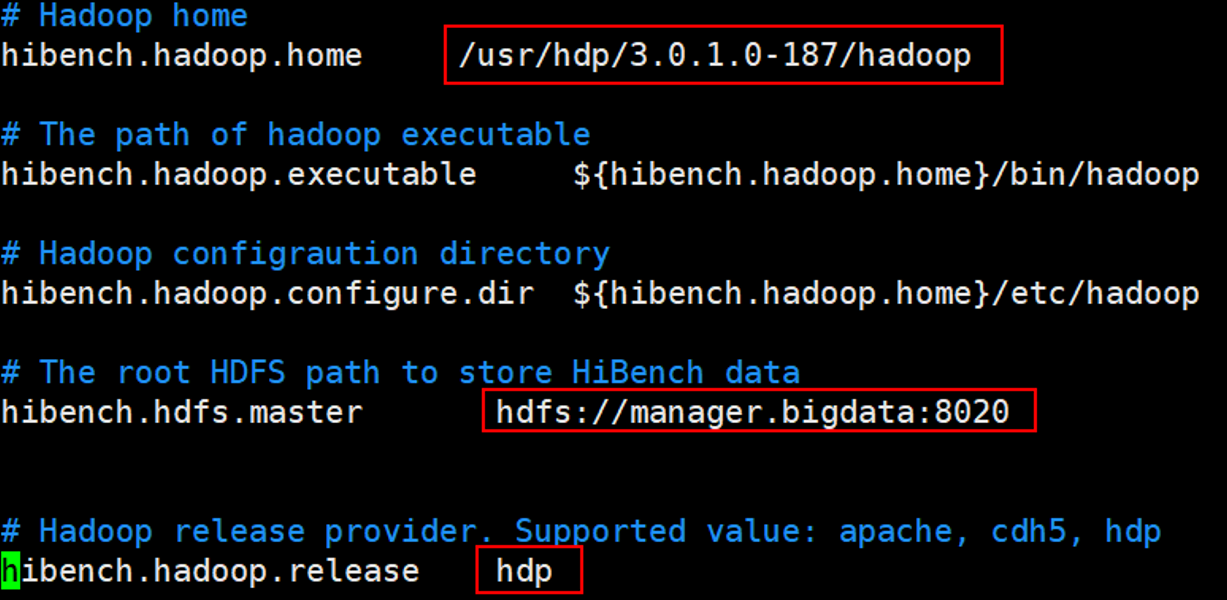
1 | cp spark.conf.template spark.conf |
修改数据量
1 | vim hibench.conf |
1 | cd workloads/micro/ |
生成数据
执行
1 | # 我的 HiBench 存放目录为:/home/erik/hibench,根据自己情况修改切换路径 |
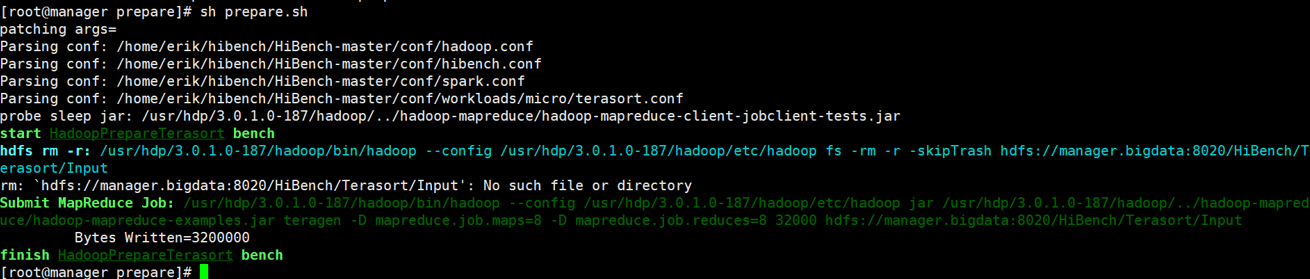
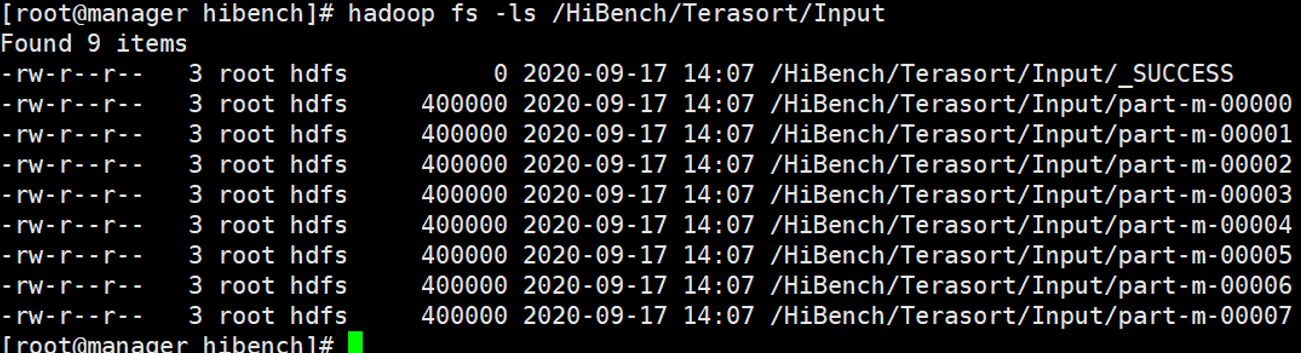
查询数据
1 | hadoop fs -ls /HiBench/Terasort/Input |
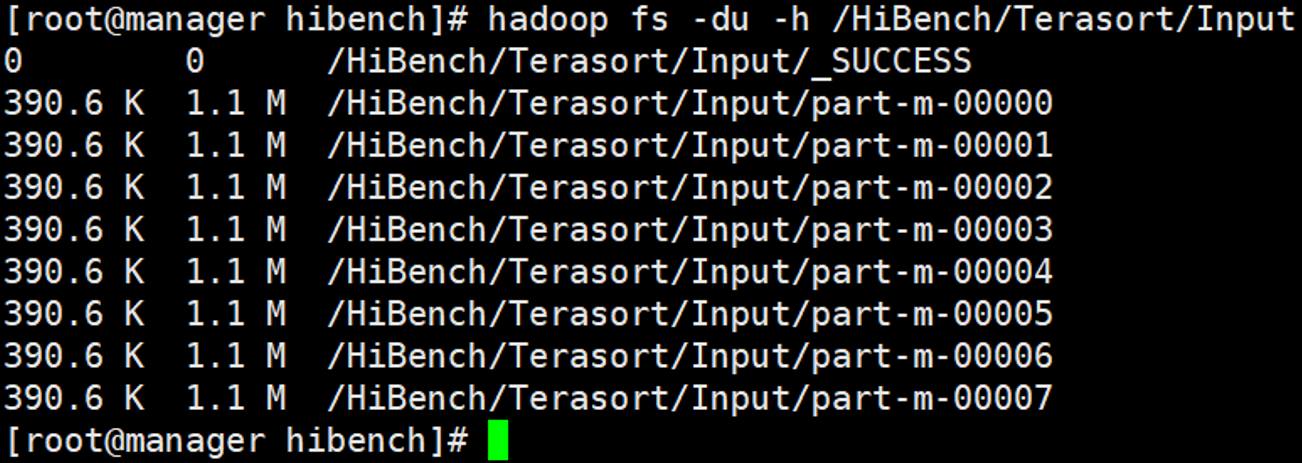
1 | hadoop fs -du -h /HiBench/Terasort/Input |
测试性能
1 | # 我的 HiBench 存放目录为:/home/erik/hibench,根据自己情况修改切换路径 |
查看测试报告
1 | cd /home/erik/hibench/HiBench-master/report |


持续时间(s) 吞吐量(b/s) 吞吐量/节点
WordCount
Spark 的 WordCount 性能测试步骤与 Terasort 步骤类似,都需要修改配置、修改数据量、生成数据、执行测试。
修改配置文件
与 Terasort 测试时一样。
修改数据量
如果需要修改数据量,可以到workloads/micro/wordcount.conf 中修改成自己想要的数据量。
生成数据
生成 WordCount 的测试数据,需要执在 bin/workloads/micro/wordcount/prepare 目录中执行 sh prepare.sh。
执行测试
在 bin/workloads/micro/terasort/spark 目录中执行 sh run.sh。
1 | cd /home/erik/hibench/HiBench-master/bin/workloads/micro/wordcount/spark |

查看报告
1 | cd /home/erik/hibench/HiBench-master/report |
测试脚本
这里提供一键测试脚本,仅供参考,主要测试 Spark 和 MR 的 Trasort 和 WordCount 在不同数据量下的测试,每种数据量执行三次。
需要提前设置好配置文件,主要包括 conf 文件夹的 spark.conf 和 hadoop.conf,以及 conf/workloads/micro/文件夹中的 terasort.conf 和 wordcount.conf 的数据量大小。脚本中的 hibench_home 根据自己的目录位置进行修改。
1 | #/bin/bash |
参考资料
[Hadoop] 使用DFSIO测试集群I/O性能_mryqu_新浪博客
http://blog.sina.com.cn/s/blog_72ef7bea0102vr44.html
linux下的缓存机制buffer、cache、swap - 运维总结 - 散尽浮华 - 博客园
https://www.cnblogs.com/kevingrace/p/5991604.html
TestDFSIO基准测试方法介绍_湖南频道_凤凰网
http://hunan.ifeng.com/a/20190613/7496675_0.shtml
如何使用HiBench进行基准测试 - 云+社区 - 腾讯云
https://cloud.tencent.com/developer/article/1158310